����2022��12��19�� /��ͨ��/ -- �˳���Ϣ���ܲá��˳�AI&HPC��Ʒ���ܾ��������ڽ��վ��е�����λ��MEET2023����δ����ᡱ�Ϸ����������ݽ���AI��ʱ�������������Ǵ���������
�ڸô�ṫ���ġ�2022�˹����������ѡ�����ϣ��˳���Ϣ����Ϊ��2022����˹������캽��ҵ������������Ϊ��2022����˹�������������

����Ϊ������MEET2023����δ�������ݽ�ʵ¼��
Ϊʲô˵���������Ǵ�������
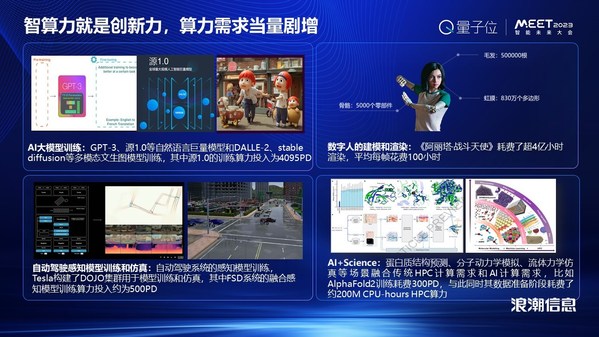
�������˹�����ǰ������Ĵ�ģ�ͣ����������������������ش��µĵ��ͣ�����GPT-3���˳���Դ1.0���ȵȣ���Щ��ģ�ͷ�չ�ı����������ļ���֧�š�
��������á���������������AI�������������������ж�������λ��PetaFlops/s-dayҲ����PD������ÿ��ǧ���ڴεļ������������һ�����ĵ�����������PD����Ϊ������λ��һ��������Ҫ����PD�ļ��������Ͱ�����Ϊ�������ġ�������������GPT-3������������3640��PD��Դ1.0��2457�ڵIJ����Ĵ�ģ�ͣ���������������4095��PD��
��ǰԪ����dz���ע�������˵Ľ�ģ����Ⱦ���棬���Ҫ��һ��������������������Ĵ�������Ⱦ���ԡ���������ս����ʹ������������ƽ��ÿһ֡��Ҫ��100��Сʱ����Ⱦ���ܹ��ⲿӰƬ����Ⱦ����ʹ����4.32��Сʱ��������
���Զ���ʻ������˹��������DOJO������ϵͳ�����ڸ�֪ģ�͵�ѵ���ͷ��档����FSDȫ�Զ���ʻϵͳ���ںϸ�֪ģ�ͣ�ѵ�����ĵ�����������500��PD��
�ڱ��ܹ�ע��AI+Science�������ʵĽṹԤ�⡢���Ӷ���ѧ��ģ�⡢������ѧ�ķ��棬�������ں��˴�ͳ��HPC����Ҳ�ں��˵����AI���㡣����˵���������ἰ��AlphaFold2������ѵ�����ĵ�����������300��PD�����ͬʱ��ΪAlphaFold2ѵ������������������Ҫ����200M CPU-hours HPC������
���ǿ���ȷ�е���ʶ����������AI������ڶഴ�±����벻����������֧�ţ�����˵���������Ǵ�������
�������ʹ����������ǰ���㷢չ��������Ҫ�����ƣ�������Ԫ����ģ�;������Լ�Ԫ���档
������Ԫ����Ҫ��Ӳһ���֧��ƽ̨
��һ��������Ԫ����Henessy��Patterson�ڼ���ǰ�ġ�������ܹ����»ƽ�ʱ������������ض��������ϵ�ܹ�Domain Specific Architectures(DSAs)�ĸ����Ҳ������������Ϊʲô�������ǻῴ����ô��Ķ�Ԫ����оƬ��
���й����г�����ʮ���ֵ�CPUоƬ���н���һ����AI������оƬ��Ϊʲô����������������������Ӧ�ó����Ƕ�Ԫ���ģ���ͬ�ij�����Ҫ��ͬ�ļ��㾫�����ͺͼ�������������˵�������ܼ���������ܻ���ҪFP64˫���ȼ��㣬AIѵ����Ҫʹ�����ַ�Χ�����ȵ͵�16λ������㣬AI��������ʹ��INT8����INT4��ʽ����Ϊ��Ӧ��Щ������ص㣬��Ҫ���������Ԫ��оƬ������֧�š���δ�������Ӳ������Ӧ����������ս���˳���Ϣ��Ϊ���ص��Ǵ�ϵͳ��Ӳ��ƽ̨�������Ƕ���������Ӧ�Ĵ���֧�š�
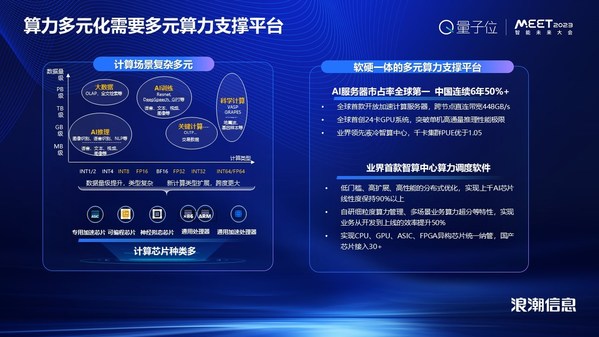
��������Ӳ�������ϵͳ֧�֣�����AI�����õķdz���Ļ��Dz���Ӣΰ��GPU��AI�����������Ƕ�������Ʒ�Ƶ�AIPU��˵��Ҫ��ʲô����һ��AI������ϵͳ��֧���أ��˳���Ϣ������ȫ����ż��ٵ�AI����������һ��ϵͳ���ܹ�֧��8�Ź���������ܵ�AIоƬ���и��ٻ������Ӷ��ܹ���ɴ��ģ��ģ��ѵ������Ҫ��������оƬ֮��ʹ���˿��ż��ٵĽӿڱ���оƬ����Խ��и���ͨ�š����죬���ϵͳ�Ѿ�����֧�ֶ��Ʒ�ƵĹ�����߶˵�GPU��AIPU�������Ѿ����ڶ�Ŀͻ���������ʵ������ء�ͬʱ������֧���Ƚ���Һ�似����ʹ�����ǹ�����AI������Ⱥ��PUE�����1.1��
��Ϊ�������ĵĺ��ģ���������ȶ�Ԫ������������һ��ƽ̨�����������ս���˳�Ϊ���Ƴ���ҵ������������������������AIStation��ʵ���˶��칹AIоƬ���б��������̻������������ܹ���ַ��Ӷ�Ԫ�칹оƬ������DZ���������ܹ������������ĵ�����Ч�ܡ��ӻ����Ľ������䵽ҵ��Ӧ�����칹������ʹ���Ż���AIStation�ṩ���걸�Ĺ��������������봫ͳ��Դ������ȣ�оƬ�����ȶ��Է�������30%�����ٽ��빤����90%���ϡ����������̻�Ҳʹ��AIStation��оƬ���������ϴﵽ��ҵ��ǰ�У��Ѿ�֧����30������������AIоƬ������X86��ARM��CPUоƬ��FPGAоƬ��Ҳ��������Ӧ�÷dz��㷺��GPU��AIPU��������Ӣΰ���GPUϵ�У��Լ��������AIPU�ȵȡ�
���������ڶ��ʵ����أ�λ�����ݵĻ����������IJ���ȫ�����ȵġ�E��AIԪ�ԡ�����ܹ���ͨ�����Ŷ�Ԫ��ϵͳ�ܹ����ڵײ������ʩ��֧��ͨ�ô�������ͨ�ü��ٴ�������ר��оƬ���ɱ��оƬ�ȣ�ͨ��AIStationʵ�����칹�����ĵ��ȣ��ṩFP64��FP32��FP16��INT8�ȶ��־��ȵļ�������֧�֣���֧�ֹ��������������ѧϰ�Ŀ�ܡ����ݿ⡢���ݼ��Խ����û���ѧϰ�ɱ���
��ģ�ͳ�ΪAIGC�㷨����
�ڶ�����ģ�͡���ģ�����ڳ�ΪAIGC���㷨���棬�����ҿ�����DALL?E����Stable Diffusion�ı����Ǵ�ģ������������ģ��ʹ��AI������ǰ�ġ������ῴ�����ߵ����조��˼�����ᴴ��������һ�������ڵ������������ܾ��ߡ��Ľ�������������֪����ģ�ʹ������ǵ�����������������ս������ܹ��Ѵ�ģ�͵������������ڶ����С��ҵ�У���������ʵ�����ܻ���ת�ͣ������ǽ���Ҫȥ�������Ҫ���⣬�������ⷽ��������ΪModel as a Service��MaaS���DZȽϺõ�һ�ַ�ʽ��
���죬�ڴ�ģ�͵������ӳ��£�AIGC�������ı����ɡ�����ͼ�Լ����������˵�Ӧ�ö�����ٵĽ��뵽��ҵ���Ρ�
��Դ1.0�����˳�ȥ���Ƴ����������Ծ���ģ�ͣ�ӵ��2457�ڲ��������ڶ������������ֳ��˷dz�����ijɼ����Ŷ�Χ�����ѧϰ��ܡ�ѵ����ȺIO��ͨ�ſ�չ�������Ż��������������ģ�͵���Ӳ��Эͬ��ϵ�ṹ��ѵ��ƽ̨������Ч�ʴﵽ45%����ңң������GPT-3��MT-NLG�����Ĵ�ģ�͡�ͬʱ��ͨ����AI�����������ѧϰ��������ϵ��Ż�����Դ���Ѿ�ʵ���˶Զ�ԪAIоƬ��֧�֡�
��������������ڡ�Դ1.0��������ʵ��Ӧ�ð�����
��һ��������AI�籾ɱ���籾ɱ�Ǵ�ұȽ���Ϥ����Ϸ��һλ�������ڡ�Դ1.0��������һ��AI��ɫ����������籾ɱ���浽�������������Ҷ����Ѳ�����Լ����ں�AIһ����籾ɱ����ΪAI�������������ֳ����ij�������������Ŀ���ԶԻ������������ڴ�ͳ��AI�㷨������Ѽ����ġ�Ŀǰ��Ŀ�Ѿ���GitHub�Ͽ�Դ����Ҹ���Ȥ���Գ��ԡ�
�ڶ����������Ϻ�һ��������Ⱥ����ڡ�Դ1.0���������������������������ڸ����ǵľ�ί�������һ������Ա��ͨ����AIģ������ί����ѯ�ľ�����������������Ӧ�Ծ���ͻ��״����������������ֽ���ģ�ͷ���Ӧ���ڽ�������İ�����AI��չ�����˸�������ռ䡣

�������Ҷ�������ChatGPT������˵�����ǻ��ڴ�ģ�͵������ı������ֶԻ���AIGCӦ�á���ʵ���ǻ��ڡ�Դ1.0��Ҳ�����˹���д�����֡����ڴ��ϣ���и�������Э��д�ܽᱨ�桢ѧϰ��ᣬ��������ϣ������һ��д��������������ҽ��г����Ĵ��������У�����ͻ���˿ɿ��ı��������ɼ���������˳��ı�����ƫ�����⣬�����ı�������һ���Ըߴ�96%���������Ż�ʹ�����ǵ�����д�������ܹ������dz�����Ч����Ŀǰ���ǵIJ�Ʒ�����ڲ�Σ���ӭ���������ʹ�á�
���ǰѡ�Դ����ģ��Ӧ�����˳��Լ���ҵ���ϣ���������ҵ�����ܻ�ת�͡��˳���Ϣ���й����ȫ��ڶ��ķ��������̡�����ӵ��һ�����Ƿdz��㷺�Ŀͻ�����ϵͳ����ͳ�����ܿͷ������ǻ��ڹ����������֪ʶ���������ʴ�ϵͳ���������ʴ�ϵͳ��������Dz��ܰ�ͻ�����ؽ������ġ�������ڡ�Դ1.0���������˳���Ϣ���ܿͷ����Խ��г��ı����������ɣ��ܹ������ض��ֶԻ���ͬʱ�dz���Ҫ�������������ǻ���֪ʶ������������ʴ�ϵͳ���������Լ�ȥ�Ķ��ͷ�������صIJ�Ʒ�����ĵ�������˵����ν�Ƿ������ġ�������ԡ���������֧���£��˳���Ϣ�Ŀͻ�����Ч�ʵõ��˴���������������Ŀ�ٻ��ˡ�������ҵ���ۡ����ア��������¼���ͻ�ƽ���
Ԫ������Ҫǿ�������������ʩ
������Ԫ���档��ҿ��ܻᾪ��Ԫ������Ҫ���������Ǹ��ߴ�ң�Ԫ����dz���Ҫ������Ԫ����Ĺ������ĸ������ҵ���ڣ�Эͬ�������߾����桢ʵʱ��Ⱦ�����ܽ�����ÿһ���������涼��Ҫ����������֧�š�����˵���ڸ߾�����ĽΣ�Ҫʵ��Ԫ���泡���б���ġ������������ɵķ��棬������ҪAI���㣬ͬʱ����ҪHPC��������ͼ����Ⱦ���ڣ�������ͳ�Ĺ����١�·���ٵ�ͼ����Ⱦ�㷨��Ҫ�����������������AI��DLSS���㷨Ҳ������֧�š������������ܽ������ڣ������������������ˡ����ֵ����Խ����ȵȣ��������ǻ��������ŵ���ʵ�֣������Ϊʲô˵Ԫ������Ҫǿ�������֧�֡�
�����˳���Ϣ�Ƴ���MetaEngineԪ�������������Ϊ��Ӧ��������������ս������Ȥ�Ŀ��Կ���������λ���MetaEngine���������������˺�����������ȫ���̡�

Ϊ���ƶ���Ԫ����Ŀ�����أ��ϸ������������������˳���Ϣ�����Ǻ���������Ƽ�һ��ǩԼ���������Ԫ�����������ģ�����֧��������㽭�����ڳ�������Ԫ��������ֿռ䴴�������ֲ�ҵ��չ��֧�����־��á���ʵ�ںϵķ�չ��
�ҵ��ݽ����˽�����лл��ң�

 ���������� 11010502030597��
���������� 11010502030597��

